You must be familiar with java compile errors, the most common ones being syntax errors, missing return statements, using uninitialized variables, attempt to access non-static members from static method, etc..
The compiler is optimized to detect them for you and asks you to correct them before they can be run. However, compiler's ability to detect errors is limited. Some errors are not known until runtime. These are called exceptions. On most of the sites, you must have heard it to be 'abnormal' or 'unexpected' but the whole gist of it is the fact that they are undetermined at compile time.
So why care about something you cannot handle anyway.. You can always run and check what error it gives !
Hmmm, first of all handing over an unpredictable code is a bad idea. Secondly, hurray!! We can handle exceptions. We may not be able to be precise on what exactly may go wrong during runtime but then we can make use of the known types of exceptions a particular task may throw.
Then there are exceptions which are caused due to logical errors. We are expected to make the code bug free rather than handling them. They are called as Runtime Exceptions. It is optional to handle it.
Then what are errors? In java exception terminology, 'Error' is beyond the reach of a programmer. They cannot be predicted or recovered from. They are caused mainly at hardware level and not our concern !!
By the way, in java, Exception (which actually is an event) is class-ified and any exception (but not error) thrown are objects of this class - Exception.
Lets clarify more on the above:
A look into Exception classes and Hierarchy now:
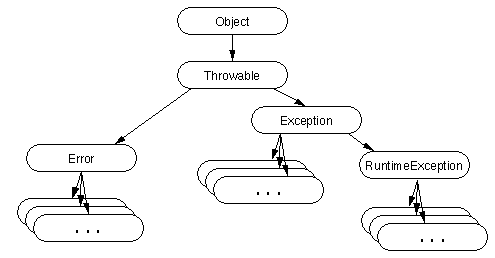
We know by now that all classes have java.lang.Object as a superclass directly or indirectly.
You can see the class 'java.lang.Exception' which encompasses all checked exceptions and runtime exceptions.
InterruptedException
NoSuchFieldException
NoSuchMethodException
ClassNotFoundException
ArithmeticException
IndexOutOfBoundsException
ArrayIndexOutOfBoundsException
StringIndexOutOfBounds
IllegalArgumentException
ClassCastException

You must be clear with the hierarchy to proceed..
The Exception class contains some methods that we may need while handling exceptions instances:
Say your program flow is as below:
Main() -> makeTree() -> checkRoot() -> printTreeToFile()
Scenario 1:
makeTree() handles IOException.
checkRoot() handles EOFException.
printTreeToFile() throws FileNotFoundException.
Will the exception be handled? Which method will handle it?
For this, you must start to know some basic Exception hierarchies. Here's help with the same..

Since printTreeToFile() does not handle any exception, it is propagated to its calling method, checkRoot(). checkRoot() doesn't handle it too and so it's propagated to makeTree() {visualize call stack to check the flow of unhandled exception}. Now, makeTree() handles doesn't handle it BUT it handles an exception which is super to the thrown one. Therefore it is handled here !!
Scenario 2:
makeTree() handles IOException.
checkRoot() handles FileNotFoundException.
printTreeToFile() throws FileNotFoundException.
Moving along the call stack, we see that checkRoot() will handle this.. quite obvious after understanding scenario 1.
There are many such scenarios where one needs to be able to predict the flow of an exception. However, once clear with call stack and exception hierarchy, it's easy to check on the flow.
The code snippet that is anticipated to produce checked exceptions, which as per java MUST be handled, must be enclosed in try block.
For example, creating a new FileInputStream may cause FileNotFoundException which is a checked exception and must be handled. Therefore, we handle it by writing it in a try block as below.
Simple, isn't it.. Some basic rules to remember:
Example:
If the try block throws an exception which is subtype of ExceptionType1, then the first catch block will handle it
Important things here to be noted:
If a method wants its calling method to handle an exception, it can skip the try-catch-finally and just SPECIFY that the exception can be thrown with throws clause. This will cause the exception to further up to the calling method on the call stack which again must either handle it or specify it for its calling method to handle.
Example:
What happens here is, if any line of code in printTree() throws an exception or if any exception has propagated to this method, then as it has specified using throws clause, this exception will be handled to its calling method to be handled. Note that the exception that has been specified here is IOException and therefore only this exception can be propagated. For all other exceptions it may throw, it should handle or specify.
We can create and throw exceptions as well.
Example:
Note that 'throw' can be used to throw a java.lang.Throwable exception which means it can throw checked and runtime exception.
In the above example, EmptyStackException is a runnable exception (unchecked). Runtime exceptions indicate invalid client code or invalid usage of client API. Throwing this runtime exception will give the client useful information on recovery.
If you want to write a checked exception that is automatically enforced by the Handle or Declare Rule, you need to extend the Exception class.
If you want to write a runtime exception, you need to extend the RuntimeException class.
Example:
There is not much of space science to it. The gist of this lies in how you can utilize this feature in your logic.
Already Tired??
Well, we are done with the basics but this topic is more about how well you can put it to use rather its than rules and syntax.
Runtime exceptions and Errors are together called, 'Unchecked exceptions'.
Runtime exceptions can be fixed by bug fixes and through logic. They mean to serve Programmer Error.
Errors are not in our hands.
In Java, there is this class - Exception. Any exception thrown is an object of this class. ;)
Every try block MUST be succeeded by EITHER catch block OR finally block.
All three blocks can also be written if required.
A try block can have multiple catch blocks.
It can have only one finally block ATMOST.The compiler is optimized to detect them for you and asks you to correct them before they can be run. However, compiler's ability to detect errors is limited. Some errors are not known until runtime. These are called exceptions. On most of the sites, you must have heard it to be 'abnormal' or 'unexpected' but the whole gist of it is the fact that they are undetermined at compile time.
So why care about something you cannot handle anyway.. You can always run and check what error it gives !
Hmmm, first of all handing over an unpredictable code is a bad idea. Secondly, hurray!! We can handle exceptions. We may not be able to be precise on what exactly may go wrong during runtime but then we can make use of the known types of exceptions a particular task may throw.
For this, lets classify Exceptions on the basic of how they may be handled:
Some exceptions are expected to be handled for sure before compilation. These are meant to assure recovery or make the program predictable even in worse scenarios. Example, if a file that is to be opened does not exist or if a user inputs an invalid data type.. These can be foreseen and MUST be handled. These exceptions are called Checked Exceptions.Then there are exceptions which are caused due to logical errors. We are expected to make the code bug free rather than handling them. They are called as Runtime Exceptions. It is optional to handle it.
Then what are errors? In java exception terminology, 'Error' is beyond the reach of a programmer. They cannot be predicted or recovered from. They are caused mainly at hardware level and not our concern !!
By the way, in java, Exception (which actually is an event) is class-ified and any exception (but not error) thrown are objects of this class - Exception.
Lets clarify more on the above:
- Checked exceptions MUST be handled. They mean to serve User Errors.
- Runtime exceptions and Errors are together called, 'Unchecked exceptions'.
- Runtime exceptions can be fixed by bug fixes and through logic. They mean to serve Programmer Error.
- Errors are not in our hands.
- In Java, there is this class - Exception. Any exception thrown is an object of this class ;)
A look into Exception classes and Hierarchy now:
We know by now that all classes have java.lang.Object as a superclass directly or indirectly.
You can see the class 'java.lang.Exception' which encompasses all checked exceptions and runtime exceptions.
Some common checked exceptions are:
InstantiationExceptionInterruptedException
NoSuchFieldException
NoSuchMethodException
ClassNotFoundException
Runtime Exceptions:
NullPointerExceptionArithmeticException
IndexOutOfBoundsException
ArrayIndexOutOfBoundsException
StringIndexOutOfBounds
IllegalArgumentException
ClassCastException

You must be clear with the hierarchy to proceed..
The Exception class contains some methods that we may need while handling exceptions instances:
- getMessage() - gives info of the exception.
- getCause()
- printStackTrace() - gives info and also prints it to System.err (error o/p stream)
- getStackTrace()
So ready to write handlers?
Well, before that let us check out the flow of exceptions.Say your program flow is as below:
Main() -> makeTree() -> checkRoot() -> printTreeToFile()
Scenario 1:
makeTree() handles IOException.
checkRoot() handles EOFException.
printTreeToFile() throws FileNotFoundException.
Will the exception be handled? Which method will handle it?
For this, you must start to know some basic Exception hierarchies. Here's help with the same..

Since printTreeToFile() does not handle any exception, it is propagated to its calling method, checkRoot(). checkRoot() doesn't handle it too and so it's propagated to makeTree() {visualize call stack to check the flow of unhandled exception}. Now, makeTree() handles doesn't handle it BUT it handles an exception which is super to the thrown one. Therefore it is handled here !!
Scenario 2:
makeTree() handles IOException.
checkRoot() handles FileNotFoundException.
printTreeToFile() throws FileNotFoundException.
Moving along the call stack, we see that checkRoot() will handle this.. quite obvious after understanding scenario 1.
There are many such scenarios where one needs to be able to predict the flow of an exception. However, once clear with call stack and exception hierarchy, it's easy to check on the flow.
How do we handle exceptions?
The most awaited question so far.. For this we use try-catch-finally blocks.The code snippet that is anticipated to produce checked exceptions, which as per java MUST be handled, must be enclosed in try block.
For example, creating a new FileInputStream may cause FileNotFoundException which is a checked exception and must be handled. Therefore, we handle it by writing it in a try block as below.
try { file = new FileInputStream(fileName); x = (byte) file.read(); }
Simple, isn't it.. Some basic rules to remember:
- Every try block MUST be succeeded by EITHER catch block OR finally block.
- All three blocks can also be written if required.
- A try block can have multiple catch blocks.
- It can have only one finally block ATMOST.
What is catch block used for?
The try block is only meant to contain the lines of code that could throw exceptions. However, if the try block is followed by catch blocks, then the closest suitable block that can handle that particular exception is chosen to handle it.Example:
try { //Protected code }catch(ExceptionType1 e1) { //Catch block }catch(ExceptionType2 e2) { //Catch block }catch(ExceptionType3 e3) { //Catch block }finally { //The finally block always executes. }
Say in the above try block, ExceptionType2 is thrown.. This will be handled by the second catch block.If the try block throws an exception which is subtype of ExceptionType1, then the first catch block will handle it
Important things here to be noted:
- Finally block MUST always be placed as the last block.
- The order of catch blocks if handling exceptions in hierarchy must be from the most specific to general type of exception.
- A catch clause cannot exist without a try statement.
- It is not compulsory to have finally clauses when ever a try/catch block is present.
- Any code cannot be present in between the try, catch, finally blocks.
This is not all folks! There is a lot more to Java Exceptions..If a method wants its calling method to handle an exception, it can skip the try-catch-finally and just SPECIFY that the exception can be thrown with throws clause. This will cause the exception to further up to the calling method on the call stack which again must either handle it or specify it for its calling method to handle.
So how do we specify?
By using throws clause..Example:
public void printTree() throws IOException{
}
What happens here is, if any line of code in printTree() throws an exception or if any exception has propagated to this method, then as it has specified using throws clause, this exception will be handled to its calling method to be handled. Note that the exception that has been specified here is IOException and therefore only this exception can be propagated. For all other exceptions it may throw, it should handle or specify.
We can create and throw exceptions as well.
How to throw an exception?
For this we use a throw statement.Example:
throw new EmptyStackException();
Note that 'throw' can be used to throw a java.lang.Throwable exception which means it can throw checked and runtime exception.
In the above example, EmptyStackException is a runnable exception (unchecked). Runtime exceptions indicate invalid client code or invalid usage of client API. Throwing this runtime exception will give the client useful information on recovery.
How to declare/create exception?
All exceptions must be a child of Throwable.If you want to write a checked exception that is automatically enforced by the Handle or Declare Rule, you need to extend the Exception class.
If you want to write a runtime exception, you need to extend the RuntimeException class.
Example:
class MyException extends Exception{ }
Why would I create my own exception?
As mentioned in Oracle Documentation, if you say yes for any of the following, then it means you need to create your own exception.- Do you need an exception type that isn't represented by those in the Java platform?
- Would it help users if they could differentiate your exceptions from those thrown by classes written by other vendors?
- Does your code throw more than one related exception?
- If you use someone else's exceptions, will users have access to those exceptions? A similar question is, should your package be independent and self-contained?
What about chaining exceptions?
As we saw, we can throw an exception using throws clause. If in handle code of of one exception, you are throwing another exception and so on, then it is called chained exception.There is not much of space science to it. The gist of this lies in how you can utilize this feature in your logic.
Already Tired??
Well, we are done with the basics but this topic is more about how well you can put it to use rather its than rules and syntax.
Coffee Break:
Checked exceptions MUST be handled. They mean to serve User Errors.Runtime exceptions and Errors are together called, 'Unchecked exceptions'.
Runtime exceptions can be fixed by bug fixes and through logic. They mean to serve Programmer Error.
Errors are not in our hands.
In Java, there is this class - Exception. Any exception thrown is an object of this class. ;)
Every try block MUST be succeeded by EITHER catch block OR finally block.
All three blocks can also be written if required.
A try block can have multiple catch blocks.
Finally block MUST always be placed as the last block.
The order of catch blocks if handling exceptions in hierarchy must be from the most specific to general type of exception.
A catch clause cannot exist without a try statement.
It is not compulsory to have finally clauses when ever a try/catch block is present.
Any code cannot be present in between the try, catch, finally blocks.